
Deployment Packs were introduced to extend the available methods for deploying changes between repositories (see past documentation for further methods). Deployment Packs give the user the capability of deploying small and precise changes into repositories.
As a user you would Assemble the changes you want to Deploy; from this point a number of dependencies will be presented to you, and you can select which dependencies you want to carry across with the deployment. You would then go on to Export these from your initial repository.
The exported changes are bundled into a .PACK file - a compressed, portable representation of the elements and decisions made. The .PACK file is generally small enough to be
emailed; making data transfers much faster.
You then Deploy this .PACK file into another repository by dragging it in or explicitly importing it.
Deployment Packs are atomic - deployment will either succeed or fail safely, meaning that either your changes will integrate as a whole or they will fail as a whole. If an error is reached, the deployment will roll back instead of half integrating any changes. The .PACK files are also tamper resistant, and will not deploy if data has been lost or changed in transit.
There are three key things to note when using Deployment Packs:
- Not all Types are supported, so Processes and similar themes can't be used with Deployment Packs. o The .Pack file is only valid for the same build i.e. any .PACK file created in build 89 can only be deployed on build 89.
- The deployment will overwrite any 'newer' changes as well as 'older' data, so care must be taken when deploying to avoid lost data.
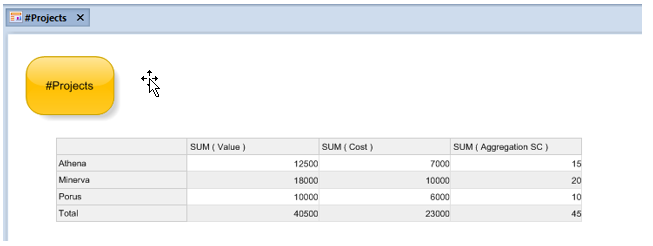
In the following Deployment Pack walkthroughs, we want to deploy an Aggregation Matrix and supporting Projects theme to another repository.
The Matrix uses a Query and a Smart Column; MooD will identify these as dependencies and ask you if they should be included in the pack.
2. Assembly Walkthrough
When assembling Deployment Packs, there can be many dependencies between elements and components. All require decisions to be made by the end user.
Deployment Packs can be found in the Libraries area.
The Deployment Packs editor has two tabs:
- Assemble to create and export packs and
- Deploy to import and deploy packs.
This sequence of steps will use the Assemble tab. You only use the Deploy tab in repositories that you are deploying into.
- In the ribbon go to the Home tab > New.
- Create a new Deployment Pack and name it appropriately.
• Give the Deployment Pack a description.
• Drag what you want to deploy into the left panel - Summary.
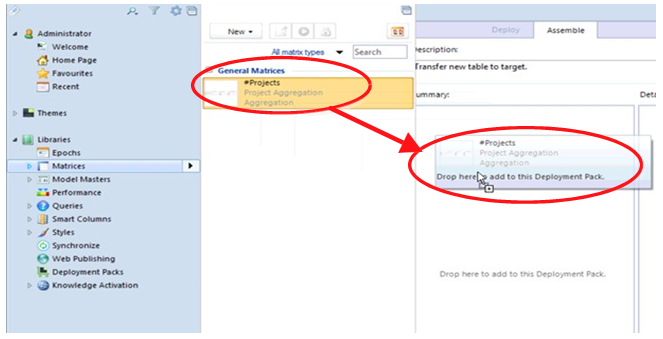
• Alternatively, you could use the Add button.

• A number of decisions will appear based on what you are deploying and what its dependencies are.
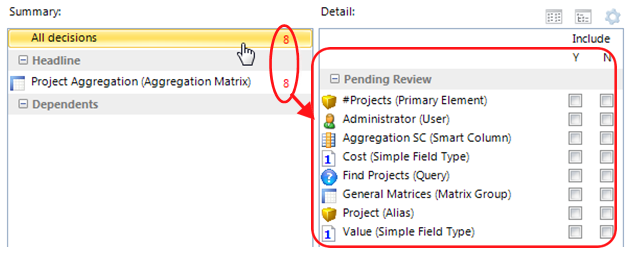
• You must decide what to include and exclude (excluded items must exist in the target).
• The number of decisions will keep changing as you include and exclude items. Work through all of the decisions.
• If you know your target repository should contain an element, and you do not want that element updated in the target, do not include it in the pack.
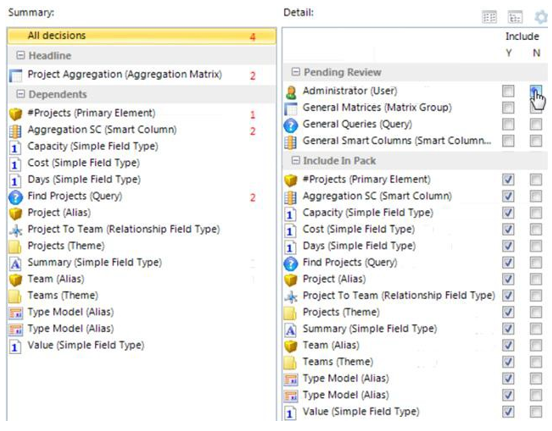
• You cannot export the pack whilst decisions remain.
• You can multi-select (with the shift key) to tick/untick in a group.
• Once all of the decisions have been made, save and then Export your Deployment Pack.
• Now you have an exported Deployment Pack in a file (.PACK) that can be distributed and deployed.
3. Deployment Walkthrough
This next sequence imports and deploys the pack in the target repository.
• Open the target repository.
• Go to Manage Repository.
As you can see, it doesn't include the Projects theme we are demonstrating. This will be brought in as one of the dependencies included in the pack.
• Open the Deployments Packs library, and click on the Deploy tab.
• In the ribbon select Home tab > Import.
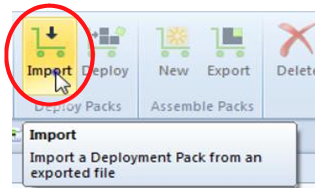
• Select the .PACK file that you want to import
• Now in the ribbon select Home tab > Deploy.
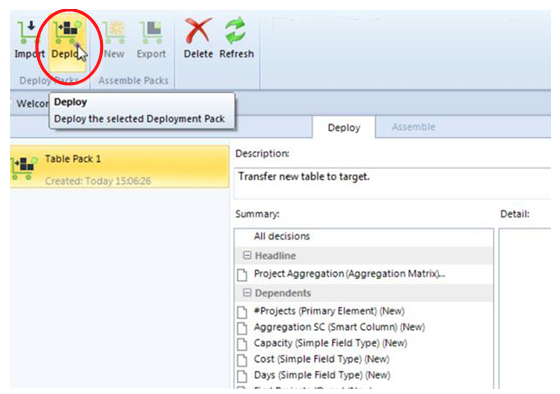
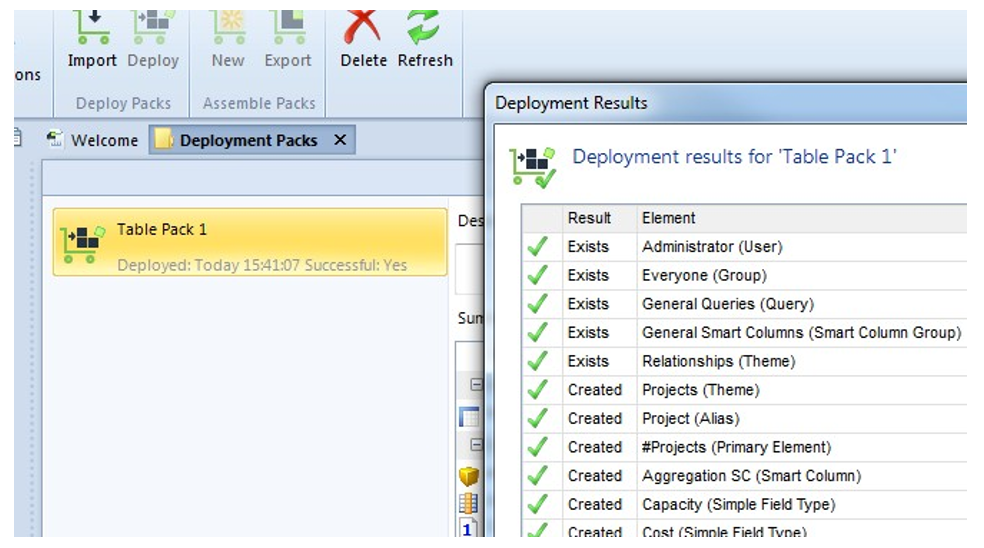
• As you can see, the target repository now includes the Aggregation Matrix and its dependencies (such as the Projects theme).
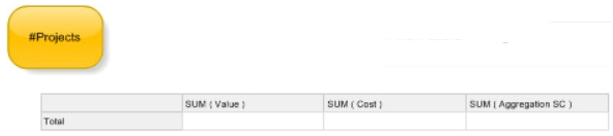
You may notice that the Matrix has been imported, but the results are different.
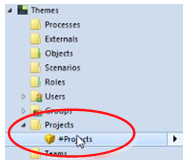
This is because, in this example, we only imported the Matrix definition and its Queries - but not the elements and fields representing the datapoints.
o Generally, a database import SAT would be more efficient than Deployment Packs for transferring large amounts of data.
• Back on the Deploy tab, you can now review the deployment history.
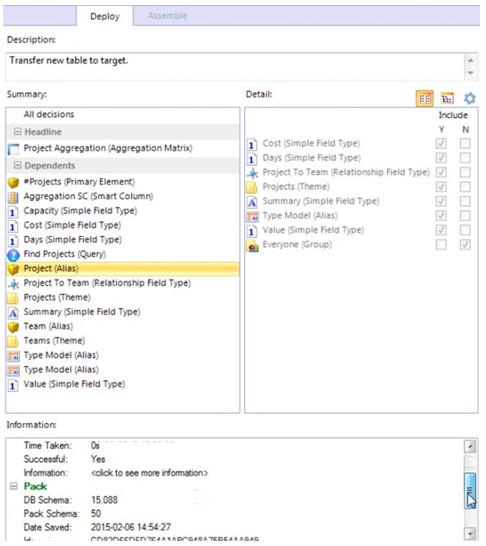
• If a deployment succeeds, it says "Yes" in the Successful row.
• You can click "<click to see more information>" in the Information row to see a list of what actions the deployment took. MooD maintains a deployment history for later inspection.
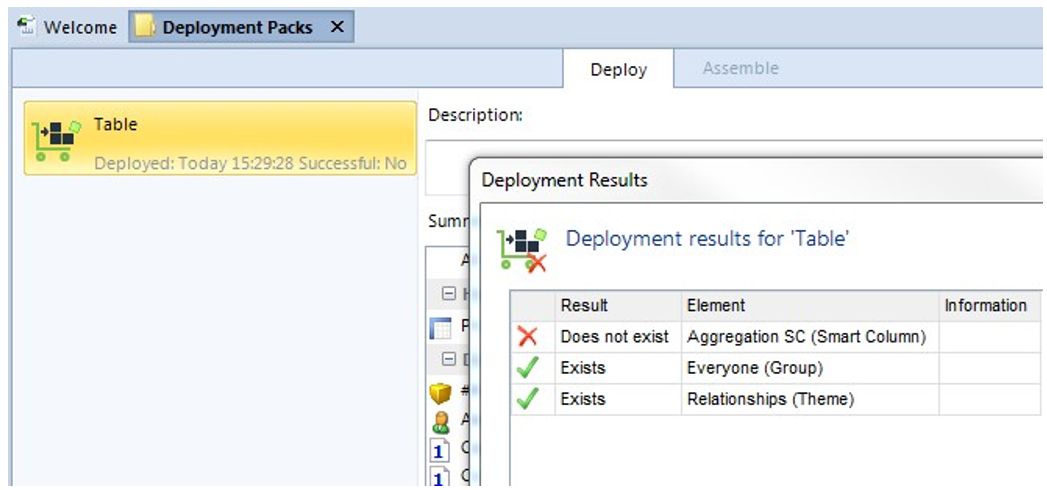
• If a deployment fails, you are told why. For example, here a required Smart Column doesn’t exist in the target and isn’t in the pack. There are no partial deployments. MooD will do everything or nothing.
Comments
1 comment
Too shallow depth. If the deployment pack you are building moves beyond the complexity shown here, the article is of very limited use.
To improve the usability a related, in depth article would be helpful. It would need to tell me what the different qualifiers mean and when I should bring them in or not. Example:
- Should I bring in a [Field type] because the elements I am bringing in are using this [Field type], even though I know this [Field type] exists in the target repository? I.e. does me selecting the [Field type] mean I want to bring in the [Field type] or does it mean I want to bring in what is stored in the [Field type] for my elements? (I can make guesses and assumptions, but to have a more definite and clear answer would be very beneficial)
Please sign in to leave a comment.